On the Nature of Bias Percolation: Assessing Multiaxial Collaboration in Human-AI Systems
Abstract
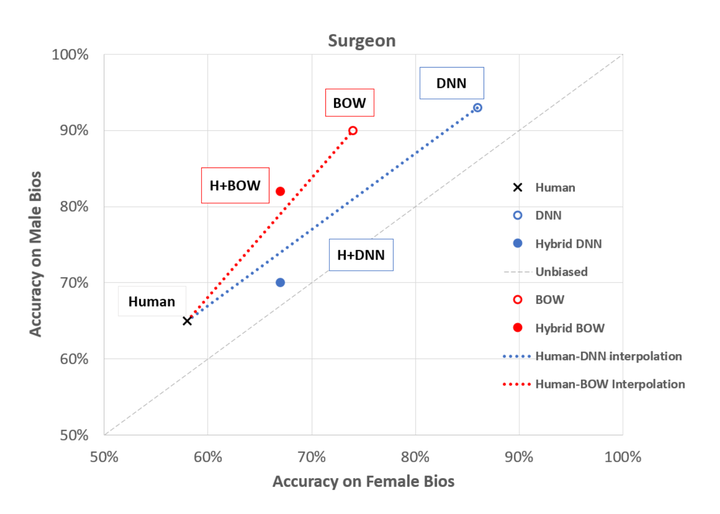
Because most machine learning (ML) models are trained and evaluated in isolation, we understand little regarding their impact on human decision-making in the real world. Our work studies how effective collaboration emerges from these deployed human-AI systems, particularly on tasks where not only accuracy, but also bias, metrics are paramount. We train three existing language models (Random, Bag-of-Words, and the state-of-the-art Deep Neural Network) and evaluate their performance both with and without human collaborators on a text classification task. Our preliminary findings reveal that while high-accuracy ML improves team accuracy, its impact on bias appears to be model-specific, even without an interface change. We ground these findings in cognition and HCI literature and propose directions to further unearthing the intricacies of this interaction.